DeepSeek-V4: A New Benchmark for Large-Scale Open-Source AI
The open-source era of 1M context intelligence
Published: 4/24/2026
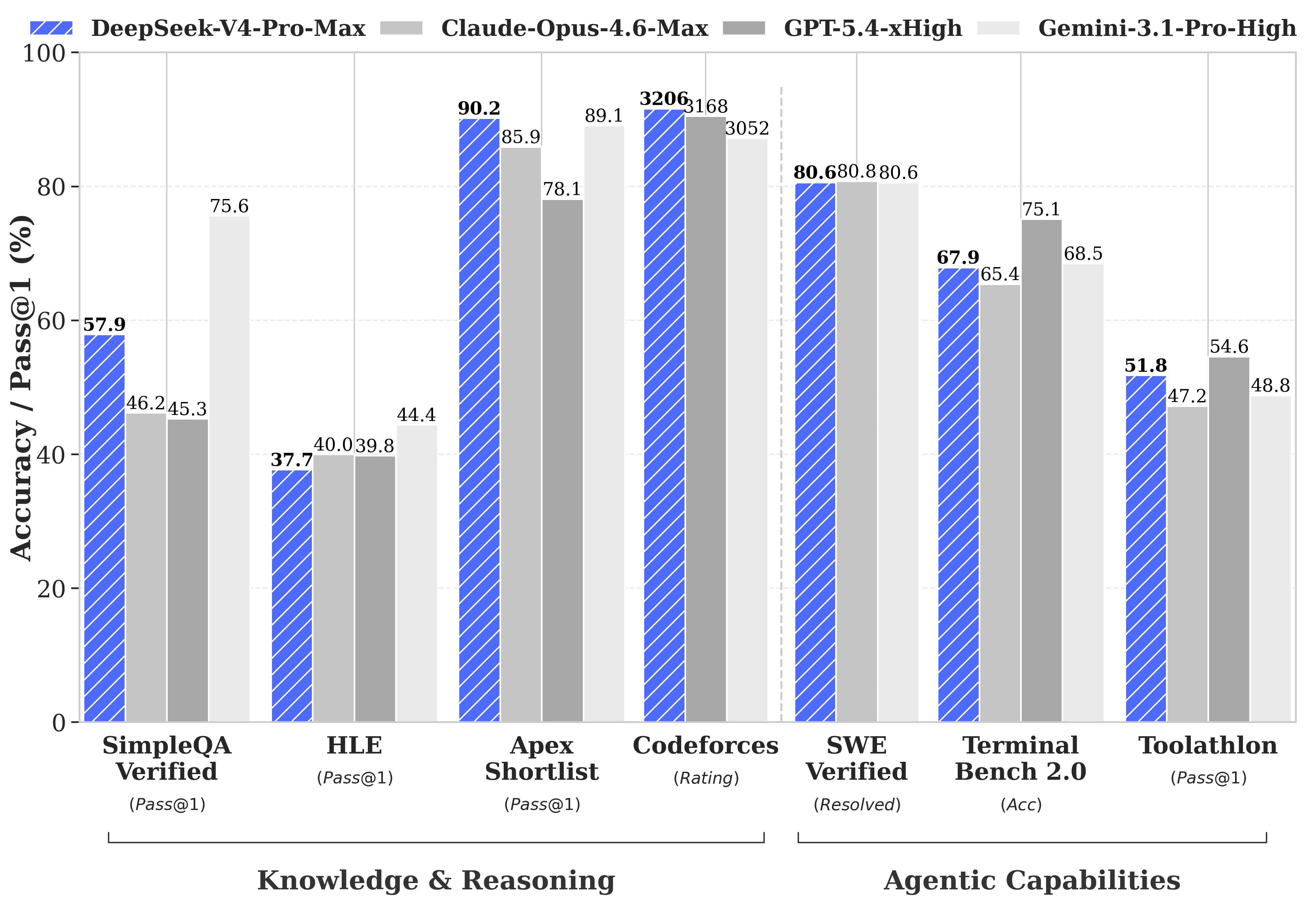
The AI landscape is shifting rapidly, and DeepSeek-V4 has arrived as a formidable contender in the open-source model ecosystem. Positioned as a highly efficient Mixture-of-Experts (MoE) language model, DeepSeek-V4 is designed to push the boundaries of what is possible with accessible intelligence. The series includes two primary variants: the V4-Pro, a massive 1.6-trillion parameter model, and the V4-Flash, a more streamlined 284-billion parameter version. Both models are engineered to handle an expansive 1-million token context window, setting a new standard for how much information an open-source model can process at once.
DeepSeek-V4 is primarily aimed at developers, enterprise researchers, and AI engineers who require deep analytical capabilities over large datasets. Whether you are performing long-form document analysis, complex multi-file code debugging, or summarizing massive repositories of technical documentation, the model’s architecture is specifically tuned to maintain coherence and accuracy across its long-context horizon. Its value proposition is simple yet profound: it offers the power of a "frontier-class" model with the transparency and accessibility of open-source software.
Solving the "Context Bottleneck"
For many organizations, the primary friction point in modern AI integration is the context window—the limit of how much data a model can "see" before it begins to hallucinate or lose track of instructions. Most current open-source alternatives struggle when pushed beyond 100k or 200k tokens. DeepSeek-V4 addresses this by utilizing a novel hybrid attention architecture.
By moving away from traditional dense model structures toward a sophisticated MoE configuration, DeepSeek-V4 drastically reduces compute and memory requirements. This solves the classic trade-off between "smart but slow" and "fast but dumb." Instead of forcing users to choose between high-cost proprietary models and smaller, less capable local models, DeepSeek-V4 fills the gap with a high-parameter, low-overhead solution that remains performant even when processing massive datasets.
Key Features & Highlights
The architecture of DeepSeek-V4 is clearly built for high-performance computing. Below are the standout features that distinguish it from the current field:
- 1M Context Window: A massive, default-supported token window allows for deep-dive analysis of entire books, large codebases, or massive legal documents in a single prompt.
- Hybrid Attention Architecture: This proprietary approach to attention mechanisms ensures that the model remains efficient in terms of KV-cache memory, preventing the common performance degradation seen in long-context models.
- MoE Flexibility: With both the V4-Pro (1.6T params) and V4-Flash (284B params) available, users can toggle between sheer reasoning power and rapid inference, depending on their hardware constraints.
- Efficiency Gains: By utilizing expert-routing, the models deliver high intelligence without requiring the massive, prohibitive energy and compute footprints of fully dense models of a similar size.
The user experience is highly optimized for those working in IDEs or integrated data environments. By reducing the compute burden per token, DeepSeek-V4 ensures faster response times during intensive tasks, which is a major quality-of-life win for developers.
Potential Drawbacks & Areas for Improvement
While the technical specs of DeepSeek-V4 are impressive, there is a natural hurdle regarding hardware requirements. Even with MoE optimizations, running a 1.6T parameter model (or even the 284B Flash version) at scale requires significant GPU infrastructure. Users without access to high-end enterprise clusters may find local deployment challenging, necessitating reliance on cloud-hosted APIs.
Furthermore, as with many new large-scale models, the "open-source" designation often comes with questions regarding specific licensing for commercial fine-tuning. Expanding the documentation around fine-tuning protocols and providing more "quantized" versions for smaller hardware setups would greatly widen the target audience for this tool.
Bottom Line & Recommendation
DeepSeek-V4 is a landmark release for anyone currently hitting the limits of their current LLM stack. It is highly recommended for developers, data scientists, and technical researchers who need to move beyond short-context constraints without sacrificing model intelligence.
If you have been waiting for an open-source solution that can actually handle massive context requirements at a high parameter count, DeepSeek-V4 is the most exciting development in the current market. Its combination of the 1M token window and hybrid attention makes it a must-try for any power user looking to build sophisticated, context-aware AI applications.
Featured AI Applications
Discover powerful tools to enhance your productivity
MindMax
New Way to Interact with AI
Beyond AI chat, transforming conversations into an infinite canvas. Combining brainstorming, mind mapping, critical and creative thinking tools to help you visualize ideas, solve problems efficiently, and accelerate learning.
AI Slides
AI Slides with Markdown
Revolutionary slide creation fusing AI intelligence with Markdown flexibility - edit anywhere, optimize anytime, iterate easily. Turn every idea into a professional presentation instantly.
AI Markdown Editor
Write Immediately
Extremely efficient writing experience: AI assistant, slash commands, minimalist interface. Open and write, easy writing. ✍️ Markdown simplicity + 🤖 AI power + ⚡ Slash commands = Perfect writing experience.
Chrome AI Extension
AI Assistant Anywhere
Transform your browsing experience with FunBlocks AI Assistant. Your intelligent companion supporting AI-driven reading, writing, brainstorming, and critical thinking across the web.