TurboQuant: Revolutionizing LLM Efficiency with Google’s Latest Compression Breakthrough
New LLM compression algorithm by Google
Published: 3/25/2026
Product Overview
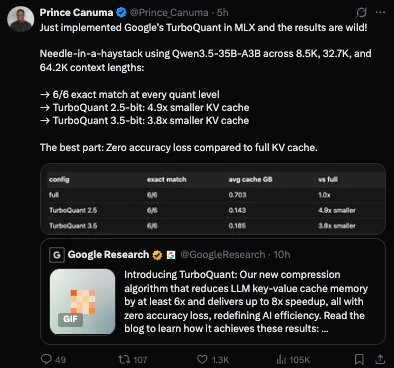
TurboQuant is a cutting-edge suite of theoretically grounded quantization algorithms developed by Google, designed specifically to tackle the resource-intensive nature of modern Large Language Models (LLMs) and vector search engines. In an era where model sizes are ballooning, making them increasingly difficult to deploy on consumer hardware or edge devices, TurboQuant provides a streamlined path to massive compression without sacrificing the performance integrity of the underlying model.
The product is primarily aimed at AI engineers, machine learning researchers, and infrastructure developers who are looking to scale their deployments while maintaining high-speed inference. By optimizing how model weights are represented, TurboQuant bridges the gap between massive, "state-of-the-art" model architecture and practical, real-world deployment on limited compute budgets. Whether you are building an LLM-powered chatbot or an high-speed vector database for RAG (Retrieval-Augmented Generation) applications, TurboQuant serves as a critical optimization layer.
Problem & Solution
The current "AI arms race" has led to a proliferation of massive models that require immense VRAM and compute resources, often pricing out smaller startups and independent developers. Traditional quantization methods—while effective—often lead to significant "perplexity drift" or accuracy degradation, rendering high-precision tasks unreliable once compressed.
TurboQuant addresses this by offering a more sophisticated, theoretically grounded approach to quantization. Rather than applying a blanket, lossy compression, TurboQuant utilizes advanced algorithms that preserve the semantic nuances of the model weights. This effectively fills the market gap between "brute-force" model pruning and full-precision model deployment, allowing teams to run larger, more capable models on smaller hardware footprints with minimal accuracy loss.
Key Features & Highlights
TurboQuant stands out due to its technical rigor and versatility across different AI architectures. Key highlights include:
- Advanced Quantization Algorithms: Built on solid mathematical foundations, these algorithms ensure that the model retains its predictive capability even under significant compression ratios.
- Vector Search Optimization: Beyond standard LLMs, TurboQuant offers specialized compression for vector search engines, drastically reducing memory latency and increasing search throughput for massive datasets.
- Seamless Integration: Designed to plug into existing machine learning pipelines, making it easier for teams to adopt these methods without refactoring their entire inference engine.
- Hardware Efficiency: By reducing the memory footprint, TurboQuant enables smoother inference on GPUs with limited memory, potentially lowering cloud infrastructure costs significantly.
The user experience is centered on the promise of "more with less." By lowering the barrier to entry for running high-parameter models, TurboQuant empowers developers to experiment with more sophisticated architectures that were previously impossible to host on standard configurations.
Potential Drawbacks & Areas for Improvement
While the technical promise of TurboQuant is high, there are a few areas that could use further development. As of now, the documentation and implementation guide may present a steep learning curve for those who are not deeply embedded in the intricacies of quantization research. Providing more "out-of-the-box" presets or a user-friendly CLI tool would greatly assist developers who need quick implementation without manually tuning every parameter.
Additionally, as the landscape of LLM quantization is rapidly evolving, users would benefit from clearer benchmarks comparing TurboQuant against popular alternatives like AWQ or GPTQ. Providing a more robust set of comparative case studies would help teams decide if this is the right compression strategy for their specific model architecture and use case.
Bottom Line & Recommendation
TurboQuant is a powerful, must-try tool for any organization or developer serious about scaling LLMs and vector search infrastructure. By leveraging Google’s research-backed compression techniques, it provides a viable pathway to reducing costs and improving efficiency without compromising the "intelligence" of the model. While it requires a bit of technical expertise to implement effectively, the ROI in terms of hardware savings and deployment speed is substantial. If you are struggling with the memory demands of large-scale AI, TurboQuant is a sophisticated solution that deserves a place in your optimization toolkit.
Featured AI Applications
Discover powerful tools to enhance your productivity
MindMax
New Way to Interact with AI
Beyond AI chat, transforming conversations into an infinite canvas. Combining brainstorming, mind mapping, critical and creative thinking tools to help you visualize ideas, solve problems efficiently, and accelerate learning.
AI Slides
AI Slides with Markdown
Revolutionary slide creation fusing AI intelligence with Markdown flexibility - edit anywhere, optimize anytime, iterate easily. Turn every idea into a professional presentation instantly.
AI Markdown Editor
Write Immediately
Extremely efficient writing experience: AI assistant, slash commands, minimalist interface. Open and write, easy writing. ✍️ Markdown simplicity + 🤖 AI power + ⚡ Slash commands = Perfect writing experience.
Chrome AI Extension
AI Assistant Anywhere
Transform your browsing experience with FunBlocks AI Assistant. Your intelligent companion supporting AI-driven reading, writing, brainstorming, and critical thinking across the web.