Claude Code Review: The Multi-Agent Approach to Bulletproof AI-Generated Code
Multi-agent review catching bugs early in AI-generated code
发布时间: 3/10/2026
Product Overview
Claude Code Review is a cutting-edge addition to the development workflow, specifically engineered to tackle the unique challenges posed by increasingly common AI-generated code. Tagged as a "Multi-agent review catching bugs early in AI-generated code," this tool elevates the standard static analysis process by simulating an expert human review team. Rather than relying on a single algorithm, Claude Code Review deploys a coordinated swarm of specialized AI agents to scrutinize every pull request (PR).
This system is targeted squarely at engineering teams, DevOps professionals, and software architects who are rapidly adopting generative AI tools (like GitHub Copilot or dedicated LLM coding assistants) but are struggling with the resulting drift in code quality, latent bugs, and security vulnerabilities introduced by these systems. The core value proposition of Claude Code Review is simple yet powerful: delivering high-signal, verified feedback directly within the PR flow, ensuring that confidence in AI-assisted development doesn't come at the expense of stability or security.
The tool is currently available in a research preview for Team and Enterprise users, signaling its focus on mature, high-stakes development environments where reliable code review is non-negotiable. It aims to instill confidence that the code being merged, even if heavily written by an LLM, has been rigorously checked by a system that understands context and potential failure modes.
Problem & Solution: Bridging the AI Code Quality Gap
The widespread adoption of LLMs for code generation has solved the problem of speed, but it has introduced a new problem: the "AI Bug Blindspot." A single-pass review, whether human or traditional static analysis, often misses subtle logical errors, security misconfigurations, or complex edge cases embedded in large chunks of machine-generated code. Furthermore, these systems are prone to generating false positives when trying to flag issues, leading to developer fatigue.
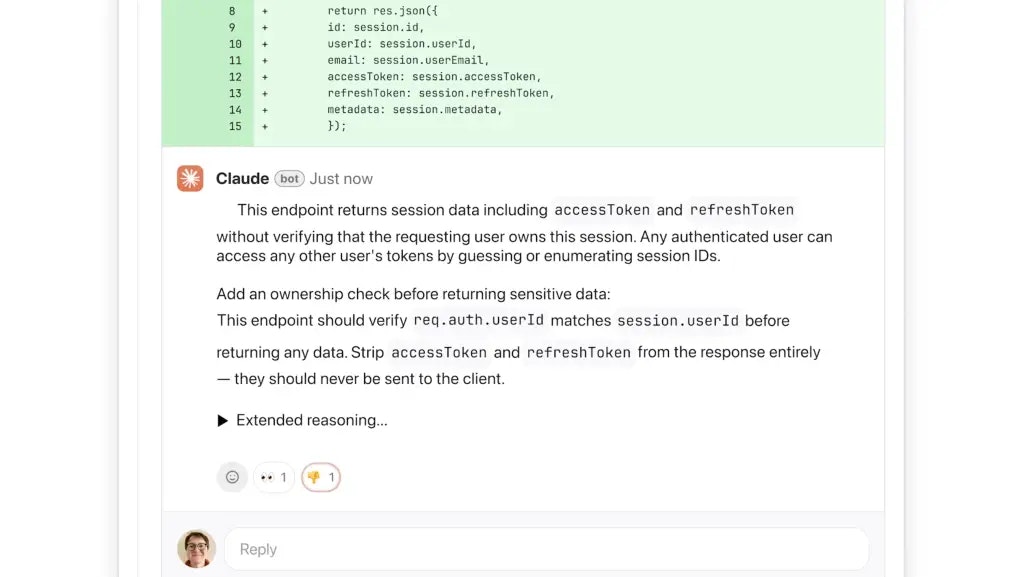
Claude Code Review solves this by transforming the review process from a linear check into a collaborative investigation. By utilizing a multi-agent architecture, the solution mimics the roles of different experts—one focusing on security, another on performance, and a third on logical consistency. These agents cross-reference findings, verify edge cases against established patterns, and only surface findings that have been corroborated, dramatically reducing the noise associated with traditional automated analysis. This verification step is key to filling the market gap for high-trust, low-false-positive code quality tooling.
Key Features & Highlights
The strength of Claude Code Review lies in its sophisticated, layered approach to code inspection:
- Multi-Agent Analysis: The flagship feature deploys specialized AI personas to analyze the PR comprehensively. This depth of review catches issues that a surface-level scan might easily miss, especially concerning complex algorithms or architectural interactions common in modern applications.
- Bug and Security Detection: The platform is explicitly tuned to detect not just syntax errors, but critical security vulnerabilities (like injection risks) and hidden logic flaws specific to patterns often favored by generative models.
- Verification for Reduced False Positives: Unlike many automated tools, Claude’s agents communicate to validate potential findings. This internal consensus-building mechanism ensures that the feedback delivered to the developer is high-signal and actionable, preserving developer time and focus.
- Seamless PR Integration: By delivering feedback directly within the Pull Request interface, Claude Code Review integrates effortlessly into existing CI/CD pipelines, making it a friction point only in the best way possible—by stopping bad code before it merges.
The user experience is designed around clarity. When issues are found, developers receive context-rich explanations detailing why the agent flagged the code, backed by specific evidence, making the learning and remediation process highly efficient.
Potential Drawbacks & Areas for Improvement
While the concept of a multi-agent review is compelling, the research preview nature suggests potential limitations that mature users should be aware of. The intensive computational requirements for running multiple sophisticated LLM agents simultaneously might lead to increased latency compared to traditional, lightweight linters. Teams must monitor the performance impact on PR processing times, especially during peak hours.
A crucial area for improvement in future iterations should focus on Customization and Context Injection. While the tool excels at general code analysis, high-performing teams often rely on proprietary internal style guides, obscure legacy patterns, or highly specific domain knowledge. Providing robust APIs or configurations to inject these custom knowledge bases into the agents' review context would transform Claude Code Review from an excellent general tool into an indispensable domain-specific guardian. Furthermore, transparency regarding the specific LLM architectures used by the agents could build greater trust with security-conscious organizations.
Bottom Line & Recommendation
Claude Code Review represents a significant maturation in the tooling landscape for AI-assisted development. It directly confronts the primary drawback of generative coding—the potential for subtly flawed output—by implementing a sophisticated, self-validating inspection layer.
This tool is highly recommended for engineering teams currently scaling their use of generative AI for codebase development and who prioritize code quality and security above all else. If your team relies on LLMs to write substantial portions of your logic and you are looking for a dependable way to verify that output without overwhelming your human reviewers, diving into the research preview of Claude Code Review should be an immediate priority. It’s a powerful step toward making AI-generated code production-ready with confidence.
Featured AI Applications
Discover powerful tools to enhance your productivity
MindMax
与AI互动的新方式
超越 AI 聊天,将对话转化为无限画布。结合头脑风暴、思维导图、批判性与创造性思维工具,帮助你可视化想法、高效解决问题、加速学习。
AI Slides
AI 驱动幻灯片,Markdown 魔法加持
革命性幻灯片创作,融合 AI 智能与 Markdown 灵活性 - 随处编辑,随时优化,轻松迭代。让每个想法,都能快速变成专业演示。
AI Markdown Editor
打开即写 - AI驱动的Markdown编辑器
极其高效的写作体验:AI助手、斜杠命令、极简界面。打开即用,轻松写作。✍️ Markdown简洁 + 🤖 AI强大 + ⚡ 斜杠命令 = 完美写作体验
FunBlocks AI Extension
🚀 AI驱动的浏览器扩展
用FunBlocks AI助手改变您的浏览体验。您的智能伴侣,为网络上的AI驱动阅读、写作、头脑风暴和批判性思维提供支持。