Fish Audio S2 Review: Directing the Future of Expressive Text-to-Speech
Real Expressive AI Voices
发布时间: 3/10/2026
Fish Audio S2 has arrived on the scene, not just as another entry in the crowded Text-to-Speech (TTS) market, but as a bold statement about the direction of synthetic voice generation. Taglined as offering "Real Expressive AI Voices," Fish Audio S2 promises to bridge the notorious gap between robotic narration and genuine human performance by introducing unprecedented levels of directorial control directly through natural language prompts. This open-source release is significant for anyone building voice applications, audiobooks, podcasts, or interactive media that demands emotional nuance.
The core proposition of Fish Audio S2 is straightforward yet revolutionary: stop scripting emotion via complex phonemes or specialized tags, and start telling the AI what you want to hear, just as you would instruct a voice actor. By making this sophisticated system open source, the team is democratizing access to what feels like next-generation synthetic voice technology, offering developers and creators a powerful new toolset for digital storytelling.
Solving the Stagnant Emotional Range of TTS
Traditional TTS systems often sound flat, lacking the subtle vocal texture required for compelling narrative. When emotion is present, it typically requires tedious, layer-by-layer fine-tuning or switching between pre-canned emotional profiles that rarely fit the specific context of a sentence. This limitation has long frustrated content creators who rely on voiceovers.
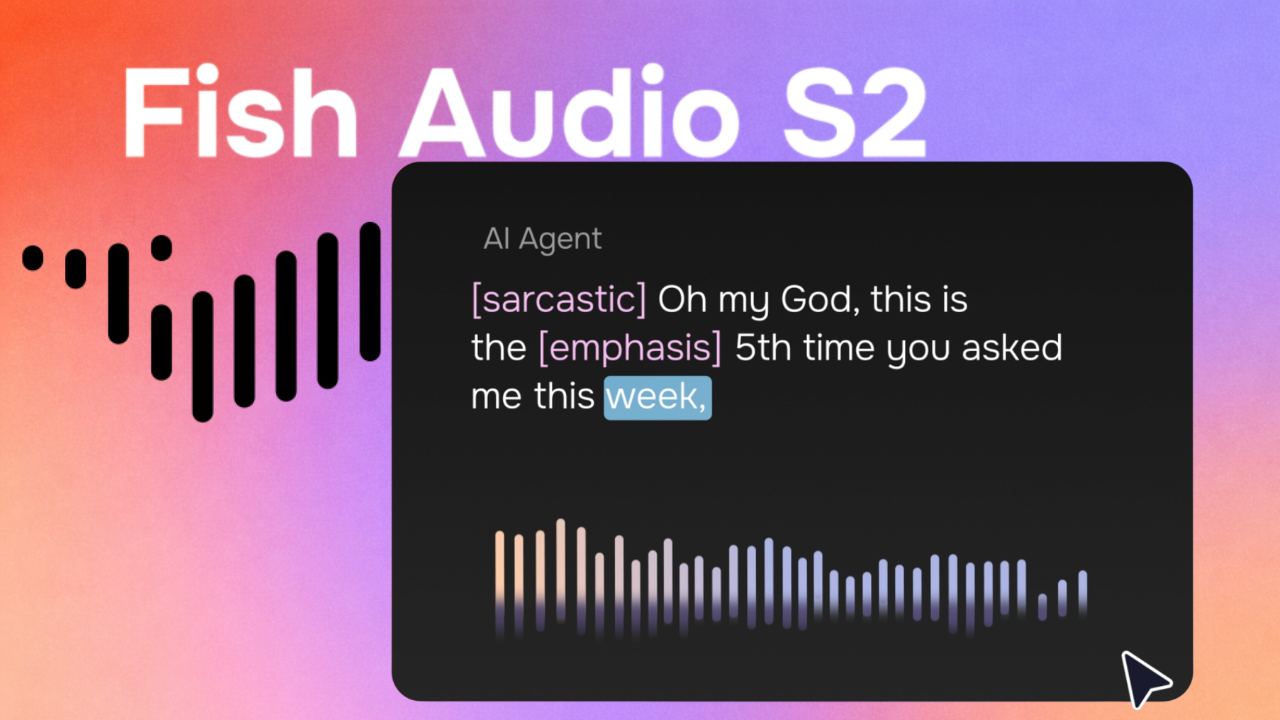
Fish Audio S2 directly tackles this rigidity. By allowing users to insert natural language cues—such as [whisper], [laughing nervously], or even [pacing quickly]—directly into the source text, the system interprets and applies that expressive direction in real-time during generation. This capability moves TTS from simple transcription to true vocal direction, filling a clear market gap for expressive, context-aware audio generation. Furthermore, the ability to generate complex, multi-speaker dialogue in a single pass significantly streamlines production workflows, a massive advantage for narrative content.
Key Features That Define Next-Gen Voice Generation
The standout features of Fish Audio S2 position it as a serious contender against proprietary, high-end voice synthesis platforms. The depth of linguistic coverage combined with granular emotional control is what truly sets this product apart.
The most impressive capabilities include:
- Natural Language Expression Directives: The ability to command vocal emotion (e.g., scared, triumphant, sarcastic) using simple text cues embedded within the script.
- Seamless Multi-Speaker Generation: Creating entire scenes with different characters speaking, all from one prompt, drastically reducing assembly time.
- Vast Language Support: Boasting scary-real voices across over 80 languages ensures global applicability for international content creators.
From a user experience perspective, the integration of these complex controls via simple text input feels incredibly intuitive. For developers integrating this into their pipelines, the open-source nature of Fish Audio S2 means full transparency and customizability, which is crucial for enterprise adoption and specialized applications.
Constructive Critique and Growth Areas
While Fish Audio S2 presents a monumental leap forward, as with any bleeding-edge technology, there are areas ripe for future development. The primary challenge in expressive AI voices always lies in consistency and nuance under extreme pressure.
One potential drawback, inherent to complex interpretive models, might be the variability in how the system interprets overlapping or conflicting cues. While the maker highlights features like [laughing nervously], users will need to thoroughly test boundary cases to ensure the intended tone is consistently achieved across thousands of unique sentences.
For future iterations, I would suggest focusing development on:
- Visualizing Directives: Providing a simple UI or visualization layer (even within the open-source interface) to map out emotional pacing across a longer script.
- Fine-Tuning Parameters: While natural language is great, offering optional parameters for adjusting the intensity of a directive (e.g.,
[whisper volume=0.3]) would give advanced users ultimate control. - Voice Cloning Integration: As this is a powerful expressive engine, exploring native pathways for cloning specific user voices while retaining these directorial capabilities would be a massive value-add.
The Bottom Line: A Must-Try for Voice Innovators
Fish Audio S2 is a game-changer for any creator, developer, or studio pushing the boundaries of synthetic media. If your projects require voices that convey genuine emotion, regional accuracy across numerous languages, and efficiency in multi-character scenes, you absolutely need to evaluate Fish Audio S2. Its open-source availability lowers the barrier to entry for state-of-the-art voice direction, promising a future where synthesized audio sounds less like a computer reading a script and more like a performance directed by you. This is not just a tool; it’s a significant step toward truly lifelike AI voice acting.
Featured AI Applications
Discover powerful tools to enhance your productivity
MindMax
与AI互动的新方式
超越 AI 聊天,将对话转化为无限画布。结合头脑风暴、思维导图、批判性与创造性思维工具,帮助你可视化想法、高效解决问题、加速学习。
AI Slides
AI 驱动幻灯片,Markdown 魔法加持
革命性幻灯片创作,融合 AI 智能与 Markdown 灵活性 - 随处编辑,随时优化,轻松迭代。让每个想法,都能快速变成专业演示。
AI Markdown Editor
打开即写 - AI驱动的Markdown编辑器
极其高效的写作体验:AI助手、斜杠命令、极简界面。打开即用,轻松写作。✍️ Markdown简洁 + 🤖 AI强大 + ⚡ 斜杠命令 = 完美写作体验
FunBlocks AI Extension
🚀 AI驱动的浏览器扩展
用FunBlocks AI助手改变您的浏览体验。您的智能伴侣,为网络上的AI驱动阅读、写作、头脑风暴和批判性思维提供支持。