MiMo-V2-Flash Review: Xiaomi’s Ultra-Fast 309B MoE Redefining Efficiency in AI Development
Ultra-fast 309B MoE model for coding & agents
发布时间: 12/21/2025
Product Overview: A New Contender in Large Language Models
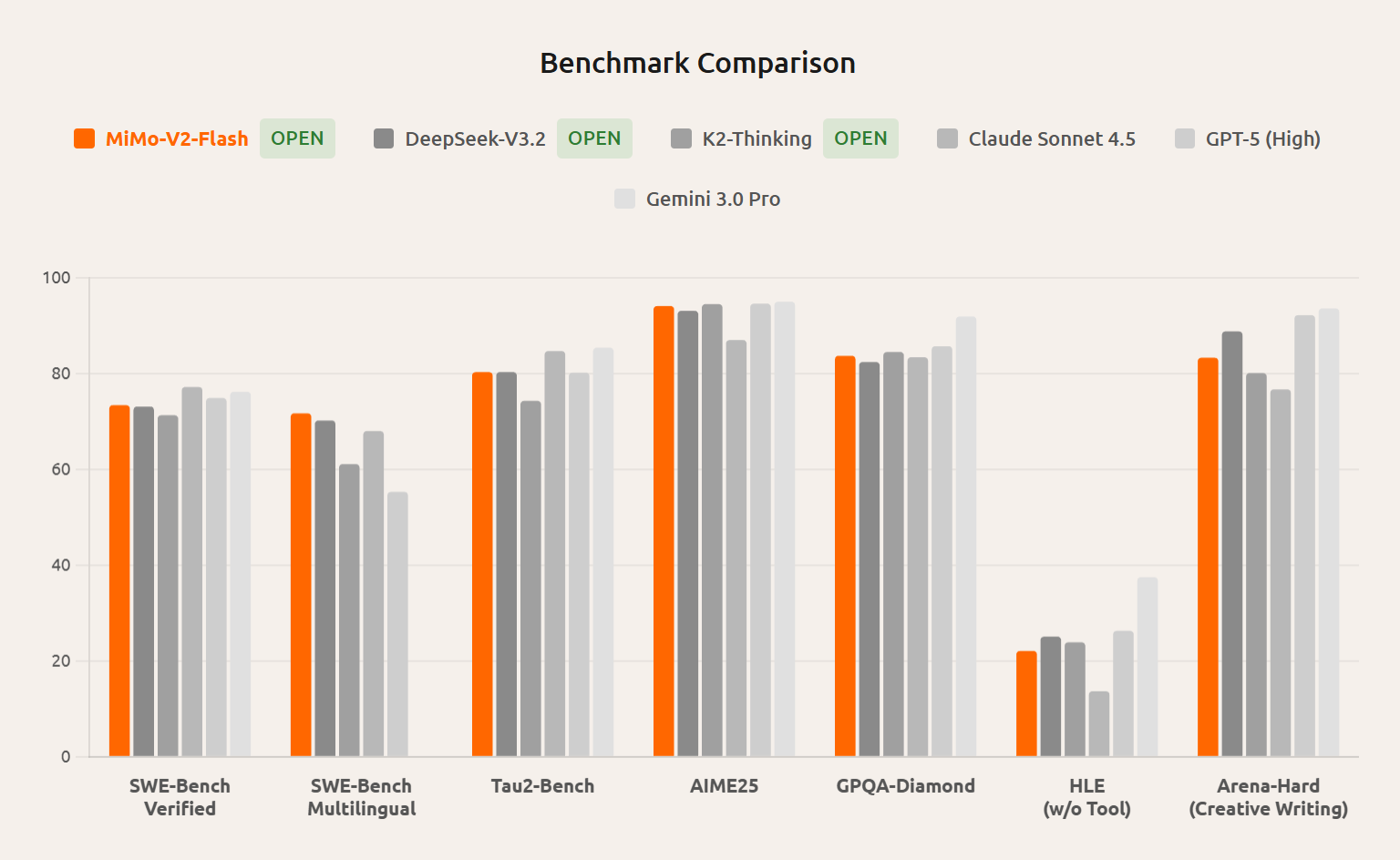
MiMo-V2-Flash enters the competitive landscape of foundation models with a compelling proposition: brute power balanced with remarkable efficiency. Developed by Xiaomi, this iteration features a massive 309 Billion parameter architecture utilizing a Mixture-of-Experts (MoE) framework, but crucially, only activates 15 Billion parameters per inference pass. This clever design choice positions MiMo-V2-Flash not just as another large model, but as a strategic tool optimized for speed without sacrificing depth of capability.
This powerful LLM targets developers, AI engineers, and sophisticated users looking to deploy high-performance AI solutions where latency is a major concern. While it serves well as a general-purpose assistant, its core strength lies in demanding technical tasks. The ability to handle complex reasoning chains, advanced coding assistance, and autonomous agentic workflows sets it apart from more generalized models.
The core value proposition of MiMo-V2-Flash is undeniable: delivering near state-of-the-art performance associated with enormous models, but with the operational speed more typical of much smaller systems. For startups and enterprises needing rapid iterations on complex AI logic, this efficiency translates directly into lower operational costs and faster user feedback loops.
Problem & Solution: Bridging the Performance-Speed Divide
The primary challenge in deploying powerful Large Language Models today revolves around the trade-off between parameter count (which correlates with capability) and inference speed (which dictates real-world usability and cost). Giants models often require immense computational resources, leading to slow response times or prohibitive GPU costs.
MiMo-V2-Flash directly addresses this dilemma through its MoE architecture. By intelligently activating only 15B active parameters out of the total 309B capacity, the model achieves superior reasoning and coding ability—hallmarks of larger models—while maintaining the swift throughput necessary for production environments. It fills a critical market gap for users who need the quality of a 300B+ class model but demand the speed of a 15B model. This makes it an ideal infrastructure layer for high-frequency agentic tasks.
Key Features & Highlights: Speed Meets Sophistication
The design philosophy behind MiMo-V2-Flash centers on maximizing utility through targeted activation. The performance characteristics of this model are its most significant selling points:
- Ultra-Fast Inference: The primary highlight is its speed. The 15B active parameter count ensures rapid response times, crucial for real-time applications like coding auto-completion or immediate decision-making in autonomous agents.
- Superior Reasoning and Coding: Despite its efficiency, the underlying 309B structure grants it a deep understanding necessary for complex software development tasks, debugging, and intricate logical problem-solving.
- Agentic Workflows: MiMo-V2-Flash is explicitly engineered for agentic scenarios. Its low latency and strong reasoning make it capable of planning multi-step actions, interacting with external tools reliably, and maintaining context over long, dynamic tasks.
- General Versatility: While specializing in technical domains, the model remains a robust, general-purpose assistant, ensuring broad applicability across various use cases.
The user experience, particularly when integrating this model via an API or local deployment (depending on accessibility), promises a substantial reduction in wait times compared to fully dense, similarly capable models.
Potential Drawbacks & Areas for Improvement
As a powerful, specialized model, the primary limitations of MiMo-V2-Flash are likely tied to its availability and operational requirements. Since the full scope of accessibility (API vs. open weights) isn't detailed, deployment flexibility might be a constraint for some users.
Constructive feedback would focus on documentation and ecosystem support. For a model emphasizing coding and agents, robust documentation detailing successful agent framework integrations (e.g., LangChain, AutoGen) and specific performance benchmarks against competitors in agentic loops would be highly beneficial. Furthermore, while the MoE structure is brilliant for speed, clear guidance on how users can potentially tune or fine-tune which experts are most engaged for specific tasks could unlock even greater specialization.
Bottom Line & Recommendation
MiMo-V2-Flash is a significant technological achievement from Xiaomi, successfully delivering top-tier reasoning capabilities within an ultra-efficient computational envelope. If your primary bottlenecks involve slow response times when running complex AI logic—especially in demanding coding environments or mission-critical autonomous agents—you absolutely need to investigate MiMo-V2-Flash.
It represents the future direction of performant AI deployment: powerful architecture made practical through intelligent sparsity. For developers prioritizing speed, accuracy, and lower inference costs in their AI toolchain, MiMo-V2-Flash deserves immediate consideration as a foundational model upgrade.
Featured AI Applications
Discover powerful tools to enhance your productivity
MindMax
与AI互动的新方式
超越 AI 聊天,将对话转化为无限画布。结合头脑风暴、思维导图、批判性与创造性思维工具,帮助你可视化想法、高效解决问题、加速学习。
AI Slides
AI 驱动幻灯片,Markdown 魔法加持
革命性幻灯片创作,融合 AI 智能与 Markdown 灵活性 - 随处编辑,随时优化,轻松迭代。让每个想法,都能快速变成专业演示。
AI Markdown Editor
打开即写 - AI驱动的Markdown编辑器
极其高效的写作体验:AI助手、斜杠命令、极简界面。打开即用,轻松写作。✍️ Markdown简洁 + 🤖 AI强大 + ⚡ 斜杠命令 = 完美写作体验
FunBlocks AI Extension
🚀 AI驱动的浏览器扩展
用FunBlocks AI助手改变您的浏览体验。您的智能伴侣,为网络上的AI驱动阅读、写作、头脑风暴和批判性思维提供支持。