Olmo Hybrid Review: A Breakthrough in Efficient Large Language Model Architecture
7B open model mixing transformers and linear RNNs
发布时间: 3/7/2026
The landscape of Large Language Models (LLMs) is constantly evolving, often forcing developers to choose between high performance and computational efficiency. Olmo Hybrid, the latest offering in the open-source AI space, boldly attempts to bridge this gap. Tagged as a "7B open model mixing transformers and linear RNNs," this model presents a fascinating architectural innovation designed to deliver high accuracy without the prohibitive computational overhead associated with pure transformer models.
Product Overview: Rethinking LLM Efficiency
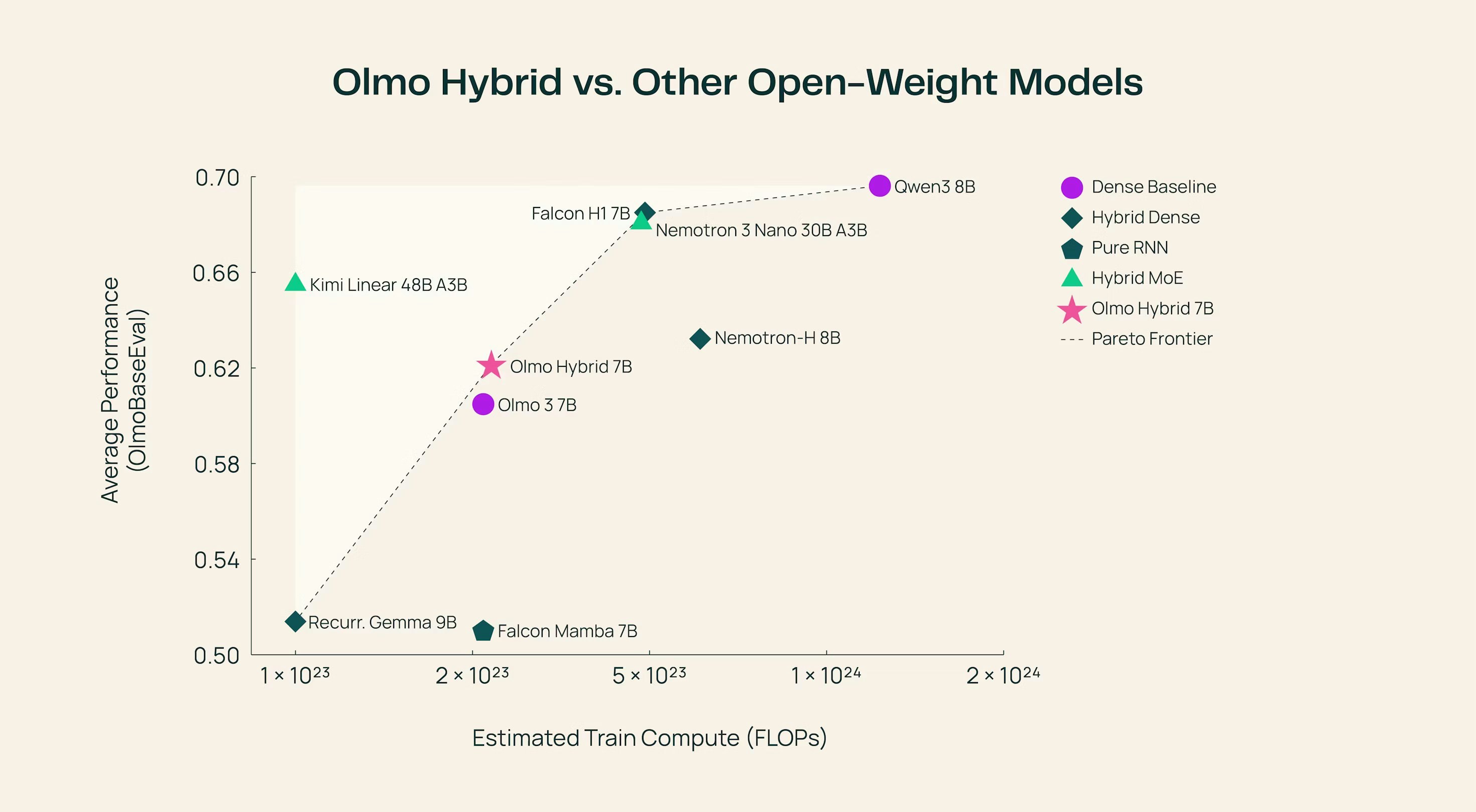
Olmo Hybrid is a significant entry because it champions openness while simultaneously pushing the boundaries of efficiency. At its core, this is a 7-billion parameter model built not just on the ubiquitous transformer architecture, but by cleverly integrating linear Recurrent Neural Network (RNN) layers. This hybrid approach suggests a departure from traditional scaling laws, aiming for smarter rather than brute-force parameter usage. The target audience here is broad, encompassing AI researchers, startups building proprietary LLM applications, and developers focused on edge deployment or cost-sensitive cloud environments. The core value proposition of Olmo Hybrid is clear: high-level performance parity with established models, achieved through drastically lower inference costs.
Problem & Solution: The Efficiency Bottleneck
The primary problem facing modern generative AI is the trade-off between context length, accuracy, and inference speed. Traditional transformer models, while incredibly powerful, suffer from quadratic complexity concerning sequence length during attention calculations, leading to slow performance and high memory usage, especially as models grow. Olmo Hybrid addresses this bottleneck directly by introducing a structural modification. It employs a specific pattern—a 3:1 ratio of Gated DeltaNet layers (likely the RNN component) to standard attention layers. This selective integration allows the model to retain the strong relational understanding provided by attention mechanisms while leveraging the linear scaling properties of the RNN components for sequence processing. This unique architectural marriage fills a critical market gap for open-source models that are both state-of-the-art and deployable economically.
Key Features & Highlights: Architectural Innovation in Action
The headline feature of Olmo Hybrid is its novel architecture. By moving away from monolithic transformer stacks, it demonstrates a viable path toward more resource-conscious LLMs. The results shared by the makers are compelling: the model matches the accuracy of the established Olmo 3 on the MMLU benchmark. However, the true achievement lies in its efficiency metrics: it accomplishes this performance using a staggering 49% fewer tokens during inference compared to its predecessor.
Key takeaways for prospective users include:
- Performance Parity: Achieves benchmark accuracy comparable to larger, more expensive models.
- Token Efficiency: Near halving of token usage suggests faster inference and lower operational costs.
- Open Source: Being fully open ensures transparency, auditability, and customizability for the community.
- Hybrid Structure: The Gated DeltaNet to attention ratio offers a blueprint for future efficient model design.
This blend of accuracy and efficiency is what makes Olmo Hybrid stand out in a crowded field dominated by pure transformer designs.
Potential Drawbacks & Areas for Improvement
While the initial performance metrics are impressive, adopting any novel architecture comes with inherent uncertainties. For Olmo Hybrid, potential users should investigate performance across a wider spectrum of tasks beyond MMLU. Current documentation might lack extensive comparisons on long-context tasks where the RNN component's effectiveness in maintaining long-range dependencies could be truly tested.
Areas for future enhancement could include:
- Extended Benchmarking: Releasing performance data on code generation, creative writing, and factual recall benchmarks would solidify confidence.
- Quantization Support: Detailed guidance and pre-optimized checkpoints for 4-bit or 8-bit quantization would immediately boost its appeal for edge deployment.
- In-Depth Documentation: A more granular breakdown of the Gated DeltaNet layer's specific role and hyperparameter tuning guidance would empower researchers further.
Bottom Line & Recommendation
Olmo Hybrid is more than just another 7B model; it represents a thoughtful evolution in LLM design, proving that architectural innovation can yield significant efficiency gains without sacrificing intelligence. If you are a researcher or developer focused on maximizing performance while minimizing cloud spend—especially in inference pipelines—you should absolutely explore Olmo Hybrid. This model is a strong candidate for replacing existing 7B models where cost savings are paramount, positioning itself as a leading example of efficient, open-source generative AI for 2024.
Featured AI Applications
Discover powerful tools to enhance your productivity
MindMax
与AI互动的新方式
超越 AI 聊天,将对话转化为无限画布。结合头脑风暴、思维导图、批判性与创造性思维工具,帮助你可视化想法、高效解决问题、加速学习。
AI Slides
AI 驱动幻灯片,Markdown 魔法加持
革命性幻灯片创作,融合 AI 智能与 Markdown 灵活性 - 随处编辑,随时优化,轻松迭代。让每个想法,都能快速变成专业演示。
AI Markdown Editor
打开即写 - AI驱动的Markdown编辑器
极其高效的写作体验:AI助手、斜杠命令、极简界面。打开即用,轻松写作。✍️ Markdown简洁 + 🤖 AI强大 + ⚡ 斜杠命令 = 完美写作体验
FunBlocks AI Extension
🚀 AI驱动的浏览器扩展
用FunBlocks AI助手改变您的浏览体验。您的智能伴侣,为网络上的AI驱动阅读、写作、头脑风暴和批判性思维提供支持。